
This article is part 5 in the series about transformation matrices:
- Part 1: Coordinate systems and transformations between them
- Part 2: Scaling objects with a transformation matrix
- Part 3: Shearing objects with a transformation matrix
- Part 4: Translating objects with a transformation matrix
- Part 5: Combining Matrix Transformations (this article)
We can compose a series of transformations by multiplying the matrices that define the transformation, for example if we have one object in the world with arbitrary position and orientation that we want to render through a camera lens located in the same world also with arbitrary position and orientation, to get the coordinates of the object relative to the camera lens we must transform the object from object space to world space (transformation known as model transform) denoted by the matrix $\mathbf{M}_{world \leftarrow object}$, and then transform the vertices of the object from world space to view space (transformation known as view transform) denoted with $\mathbf{M}_{view \leftarrow world}$
We can associate the transformation matrices and have a single matrix to transform vertices of the object directly to camera space
Now if we have two transformation matrices $\mathbf{M}$ and $\mathbf{N}$ and they are applied to some vector $\mathbf{v}$ in that respective order their product is
We can see that the rows of the product $\mathbf{NM}$ are the result of transforming the basis vectors of $\mathbf{M}$ by the transformation matrix $\mathbf{N}$ so matrix-matrix multiplication encodes a basis vectors transformation
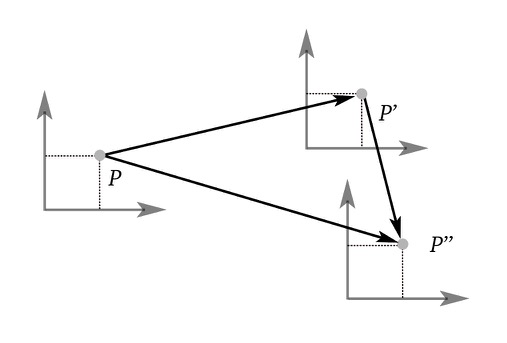
Rotation followed by translation
Given the vector $\mathbf{v}$ let’s apply a rotation and a translation transform in that order
Let’s analyze the product $\mathbf{TR}$
Which when multiplied by $\mathbf{v}$ results in
$\mathbf{v’}$ will have a compact form equal to
Translation followed by rotation
Given the vector $\mathbf{v}$ let’s apply a translation and a rotation transform in that order
Let’s analyze the produce $\mathbf{RT}$
Which when multiplied by $\mathbf{v}$ results in
$\mathbf{v’}$ will have a compact form equal to
Note that both the vector $\mathbf{v}$ and the translation vector are transformed by $\mathbf{R}$
Transformations between coordinate systems
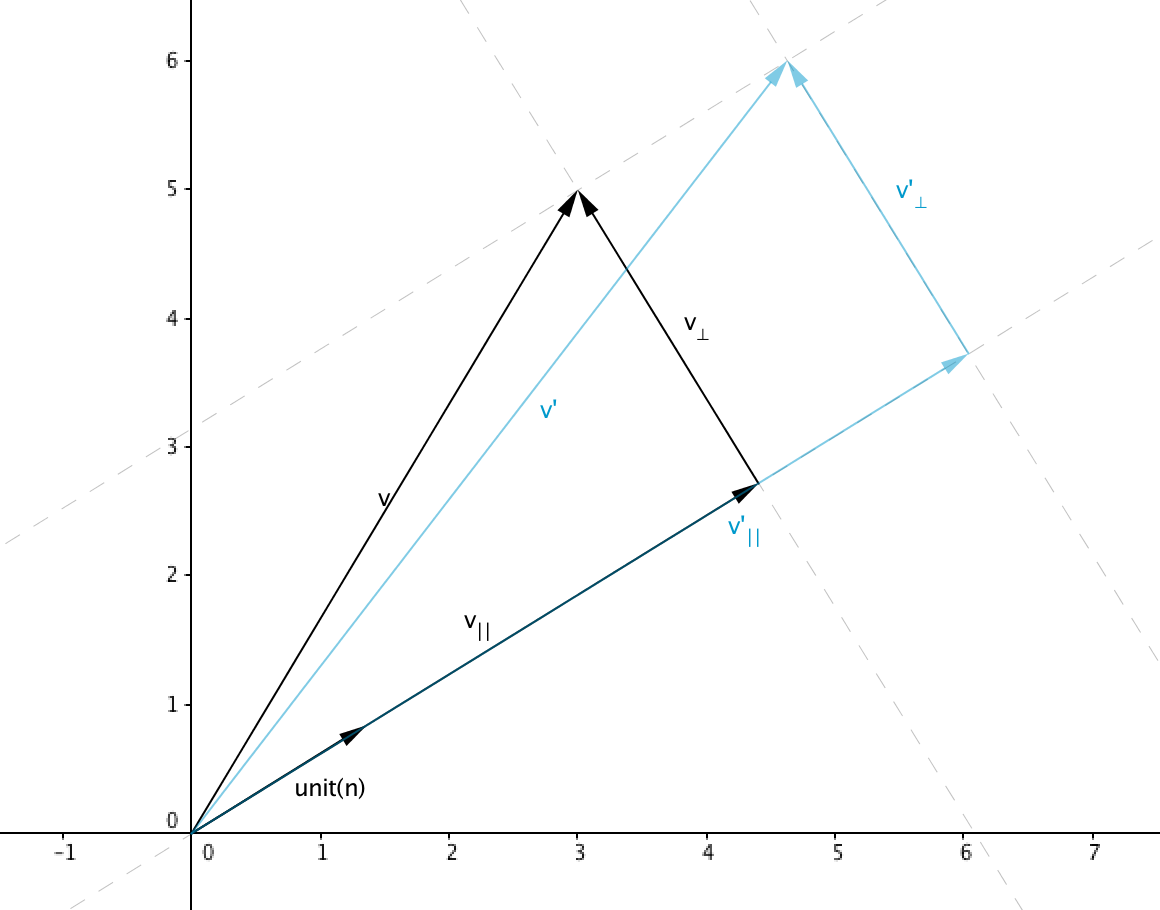
The following figure shows two coordinate system, the one with the basis vectors $\mathbf{x}, \mathbf{y}$ and $\mathbf{z}$ is the canonical coordinate system, $\mathbf{u}, \mathbf{v}$ and $\mathbf{w}$ are the basis of a nested coordinate system expressed in terms of the canonical coordinate system

coordinate systems
The value of $\mathbf{p}$ expressed in the canonical coordinate system is
Similarly we can express $\mathbf{p}$ with the following equation
Note that both equations express $\mathbf{p}$ in terms of the canonical coordinate system, we can express the same relationship using transformations matrices as a rotation followed by a translation
We can then introduce $\mathbf{p}_{uvw}$ which is the point $\mathbf{p}$ expressed in the nested coordinate system, similarly $\mathbf{p}_{xyz}$ is the same point expressed in canonical coordinate system
This is the frame-to-canonical transformation matrix for the $(u,v,w)$ coordinate space
The inverse transformation is given by a translation followed by a rotation
Which is the same as finding the value of $\mathbf{p}_{uvw}$ in \eqref{frame-to-canonical}
This is the canonical-to-frame transformation matrix for the $(u,v,w)$ coordinate space