Data Structures
There's a total of 2 articles.
Data structures for massive datasets

The algorithms that we use every day to manipulate data assume that we have access to all
the data we need. What if there’s more data that can fit in a single computer or if accessing
the data itself to do searches is expensive? If so, we can use specialized data structures
that can help us “estimate” the actual value without actually computing it, in some cases
an estimate might be good enough. These data structures are: count-min sketch, bloom filters,
and reservoir-sampling.

Memtable & SSTable (Sorted String Table)
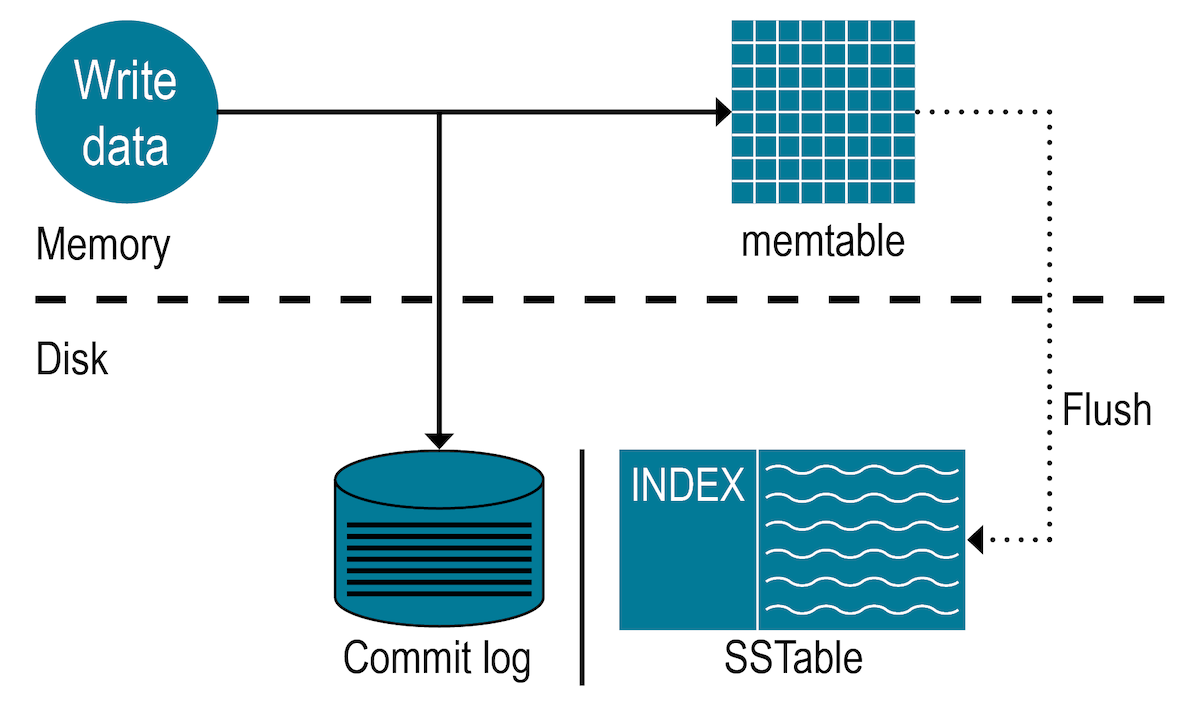
The pattern of batching data up in memory, tracked in a write ahead log, and periodically flushed to disk is ubiquitous today. OSS examples are LevelDB, Cassandra, InfluxDB, or HBase.
In this article I implement a tiny memtable for a timeseries database in golang and briefly talk about how it can be compressed into a sorted string table.