Data Modeling
There's a total of 2 articles.
Cassandra
system design
distributed systems
databases
columnar datastore
memtable
sstable
quorum
data modeling
Cassandra is a highly scalable, distributed NoSQL (non-relational) database management system designed for handling large amounts of data across multiple commodity servers.
This article covers key design features of cassandra such as the usage of consistent hashing, the write pattern to a write ahead log and a memtable, the read pattern from the memtable and from sstables, and finally and most important, some examples about data modeling for different types of queries.

Partitioning
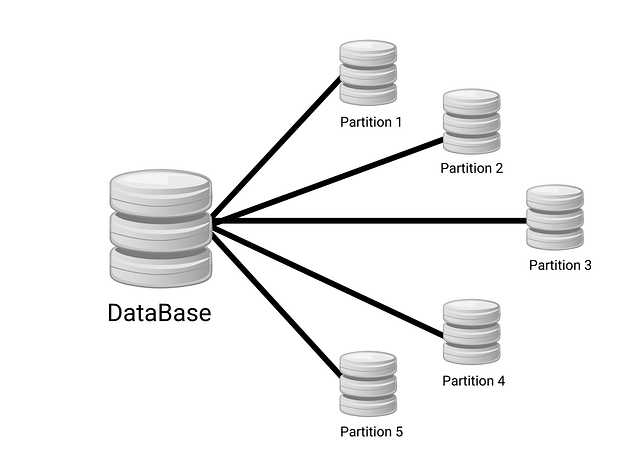
Data partitioning refers to the process of dividing a system’s data into smaller, more manageable subsets, which are distributed across multiple storage locations or nodes.
This article covers some strategies for partitioning including random partitioning, by hash key, by range and a hybrid approach for skewed workloads. We also see strategies to rebalance partitions if there's a static or dynamic number of partitions.