Engine
Features
- Consistent hashing
- Replication factor, replicas of the data across the cluster
- Consistency level controlled for each query
- Up to 2 billion key-value pairs in a row

Cassandra replication
- Replication factor = 3
- Consistency level = QUORUM
- Clients talks to any node, the node hashes the partition key and finds the location of the data
- Data is read from all the replicas waiting for responses until we reach a quorum

Cassandra write
- Acknowledged when we write to both the commit log (append only) and the memtable
- When the memtable becomes full it’s flushed into an SSTable
- Periodically SSTables are merged
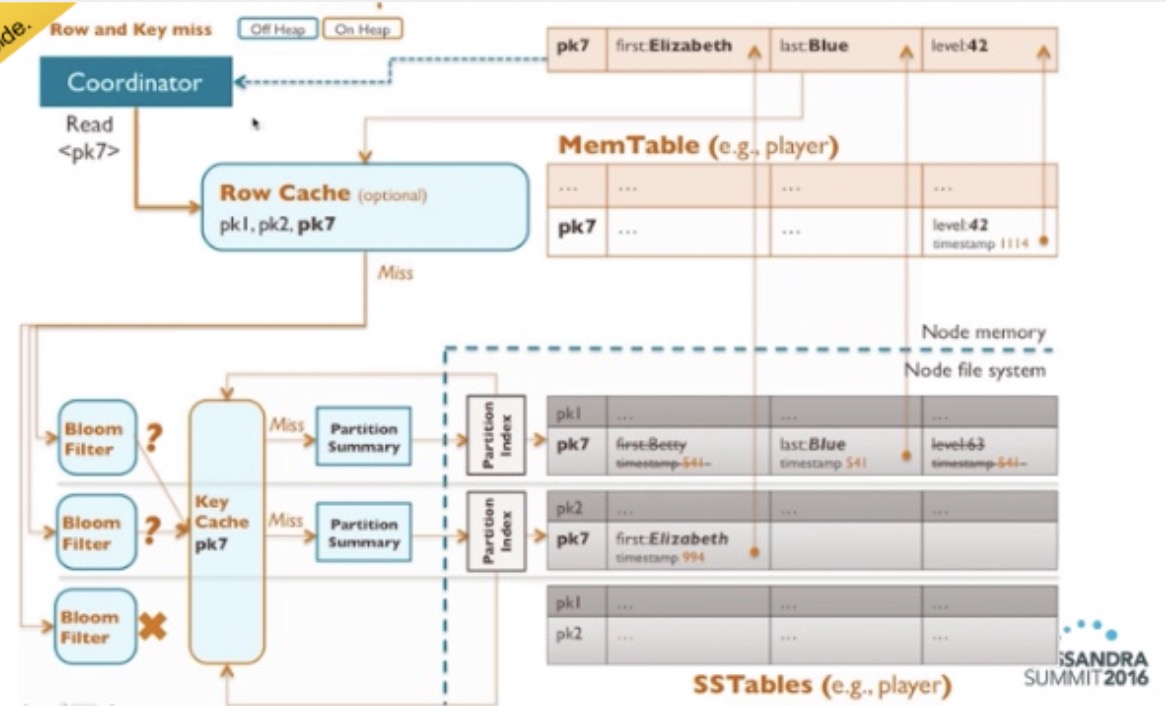
Cassandra read
- Check if the key is in the in-memory row cache
- Query the bloomfilters of the existing SSTables to find the record, if it doesn’t exist then skip the SSTable
- If the bloomfilter says that there may be data check the in-memory key cache
- On miss get the data from the SSTable and merge it with the data in the memtable, write the key to the in-memory key-cache and merged result to the in-memory row cache
Data modeling
Goals
- spread data evenly around the cluster
- minimize the number of partitions read
- keep partitions manageable
Process
- Identify initial entities and relationships
- Key attributes (map to PK columns)
- Equality search attributes (map to the beginning of the PK)
- Inequality search attributes (map to clustering columns)
- Other attributes
- Static attributes are shared within a given partition
primary key = partition key + clustering columns
Legend:
K Partition key
C Clustering key and their ordering (ascending or descending)
S Static columns, fixed and shared per partition

Cassandra table structure
Validation
- Is data evenly spread?
- 1 partition per read?
- Are writes (overwrites) possible?
- How large are the partitions? Let’s assume that each partition should have at most 1M cells, $n_{cells} = n_{rows} * (n_{cols} - n_{K} - n_{S}) + n_{S} < 1M$
- How much data duplication?
Examples
Store books by ISBN
| Attribute | Special |
|---|---|
| isbn | K |
| title | |
| author | |
| genre | |
| publisher |
- Is data evenly spread? Yes
- 1 partition per read? Yes
- Are writes (overwrites) possible? Yes
- How large are the partitions? $1 * (5 - 1 - 0) + 0 < 1M$
- How much data duplication? 0
Register a user uniquely identified by an email/password, we also want their fullname. They will be accessed by email and password or by UUID
| Attribute | Special |
|---|---|
| K | |
| password | C |
| fullname | |
| uuid |
Q1: find users by login info
Q3: find users by email (to guarantee uniqueness)
- Is data evenly spread? Yes
- 1 partition per read? Yes
- Are writes (overwrites) possible? Yes
- How large are the partitions? $1 * (4 - 1 - 0) + 0 < 1M$
- How much data duplication? 0
| Attribute | Special |
|---|---|
| uuid | K |
| fullname |
Q2: get users by UUID
- Is data evenly spread? Yes
- 1 partition per read? Yes
- Are writes (overwrites) possible? Yes
- How large are the partitions? $1 * (2 - 1 - 0) + 0 < 1M$
- How much data duplication? 0
Find books a logged in user has read sorted by title and author
| Attribute | Special |
|---|---|
| uuid | K |
| title | C |
| author | C |
| fullname | S |
| ISBN | |
| genre | |
| publisher |
- Is data evenly spread? Yes
- 1 partition per read? Yes
- Are writes (overwrites) possible? Yes
- How large are the partitions? (up to 200k book reads per user)
$$
\begin{align*}
n_{books} * (7 - 1 - 1) + 1 & < 1M \\\\
n_{books} & < \frac{1M}{5} - 1 \\\\
n_{books} & < 200k
\end{align*}
$$
- How much data duplication? 0
Interaction of every user in the website
| Attribute | Special |
|---|---|
| uuid | K |
| time | C (desc) |
| element | |
| type |
- Is data evenly spread? Yes
- 1 partition per read? Yes
- Are writes (overwrites) possible? Yes
- How large are the partitions? (up to 333k book reads per user, 333k actions may be low number of actions to store therefore we should store actions by bucket)
$$
\begin{align*}
n_{actions} * (4 - 1 - 0) + 0 & < 1M \\\\
n_{actions} & < 333K
\end{align*}
$$
- How much data duplication? 0
| Attribute | Special |
|---|---|
| uuid | K |
| month | K |
| time | C (desc) |
| element | |
| type |
- Is data evenly spread? Yes
- 1 partition per read? Yes
- Are writes (overwrites) possible? Yes
- How large are the partitions? (up to 333k book reads per user)
1 year = 333k / 365 / 24 = 38 actions / h
1 month = 333k / 30 / 24 = 462 actions / h (most realistic case)
1 week = 333k / 7 / 24 = 1984 actions / h
$$
\begin{align*}
n_{actions} * (5 - 2 - 0) + 0 & < 1M \\\\
n_{actions} & < 333K
\end{align*}
$$
- How much data duplication? 0
References
- https://www.slideshare.net/DataStax/scalable-data-modeling-by-example-carlos-alonso-job-and-talent-cassandra-summit-2016
- https://blog.emumba.com/apache-cassandra-part-5-data-modelling-in-cassandra-9e81a58f4ada
- https://www.datastax.com/blog/2015/02/basic-rules-cassandra-data-modeling
- https://tech.ebayinc.com/engineering/cassandra-data-modeling-best-practices-part-1/
- https://www.datastax.com/sites/default/files/content/whitepaper/files/2019-10/CM2019236%20-%20Data%20Modeling%20in%20Apache%20Cassandra%20%E2%84%A2%20White%20Paper-4.pdf
See Also
Partitioning
Data partitioning refers to the process of dividing a system's data into smaller, more manageable subsets,
which are distributed across multiple storage locations or nodes.
<br />
This article covers some strategies for partitioning including random partitioning, by hash key, by range
and a hybrid approach for skewed workloads. We also see strategies to rebalance partitions if there's
a static or dynamic number of partitions.

Published on Mon, Jan 8, 2018
Last modified on Sun, Nov 10, 2024
511 words
Last modified on Sun, Nov 10, 2024
511 words
Preparation for a Software Engineer interview

This is my interview preparation plan for a software engineering role,
I share a summary of my preparation, a plan of problems to tackle for
coding interviews, the topics to study for a system design interviews and
the questions to prepare for the behavioral section.
Published on Mon, Oct 12, 2020
Last modified on Fri, Nov 22, 2024
5650 words
Last modified on Fri, Nov 22, 2024
5650 words
Back of the envelope calculations

When designing a system it's important to consider the limitations of the technologies
chosen, making some approximate calculations when the system is designed help
us decide on the tradeoffs of the different approaches, these approximations include
<br />
This article has a table with latency comparison numbers, common numbers used
in system design calculations and some challenges to put all of these info into practice.
Published on Sat, Aug 8, 2020
Last modified on Sun, Nov 10, 2024
1128 words
Last modified on Sun, Nov 10, 2024
1128 words